
J.D. Zamfirescu-Pereira
I am an assistant professor in the computer science department at UCLA, studying joint human/AI systems using a systems HCI approach.
I am recruiting PhD students this cycle! Apply to UCLA Computer Science (by Dec 15, 2025) and mention my name in your application. I also have two postdoc positions available—please reach out to me directly if you believe your research interests may be a good fit for the lab!
I completed my PhD at UC Berkeley in 2025, where I was advised by Björn Hartmann and supported by a Chancellor's Fellowship and the Google PhD Fellowship; I also worked closely with John DeNero and Narges Norouzi at Berkeley, and with Qian Yang at Cornell.
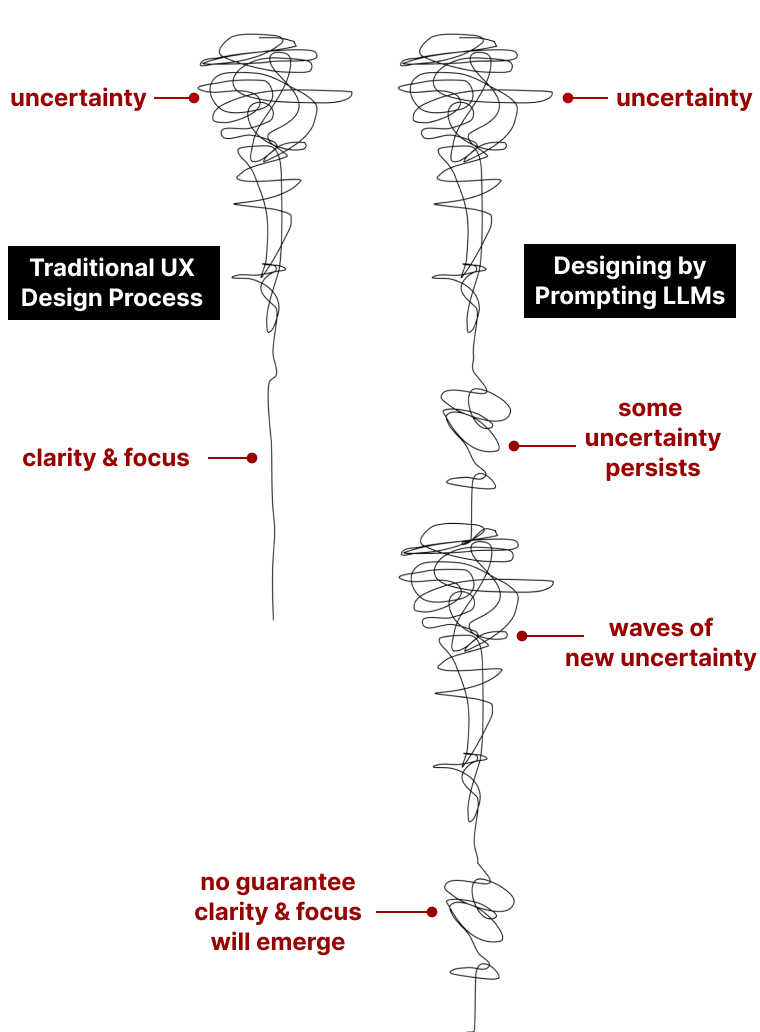
My career has been driven primarily by one question: how do we help more people do more with computing—collaboratively? In recent years this work has focused on understanding and overcoming the challenges people face working with large pre-trained models and the systems we build with them.
I also spent years teaching programming & electronics, and launching a minor in Computational Practices at California College of the Arts. Previously, I studied human-robot interaction at Stanford, and was the founder & CTO at EtherPad, an early YC company acquired by Google.
Recent & Upcoming Travel & Talks:
- Feb 26-28, 2025: Presenting 61A Bot work at SIGCSE (Pittsburgh, PA)
- April 26-30, 2025: Presenting Beyond Code Generation at CHI (Yokohama, Japan)
Research
My recent research falls into three core areas: Designers, broadly—visual arists, chatbot designers, programmers—working with and through AI and LLMs; visual, physical, and cognitive aids for CS education; and other intersctions of HCI + ML.
Highlights
Why Johnny Can't Prompt
How non-AI Experts Try (and Fail) to design LLM Prompts
Berkeley 61A TA-bot
Deployed AI assistant to 3000+ students in Berkeley's intro CS course
Herding AI Cats
Lessons from Designing a Chatbot by Prompting GPT-3
HCI + AI: LLMs, Large Pre-trained Models + Design
Beyond Code Generation: LLM-supported Exploration of the Program Design Space CHI 2025 [pdf] Best Paper Honorable Mention
J.D. Zamfirescu-Pereira, Eunice Jun, Michael Terry, Qian Yang, Björn Hartmann
Most AI-supported programming focuses on iterated code generation through chat or prompts. Here, we propose considering programming a design activity, and explore how support for program design space exploration impacts program design. Our IDE, PAIL, helps users abstract up to higher-level problems, explore a broader space of problem and solution formulations, and tracks questions, explicit and implicit decisions, and abstractions—enabling programming at higher levels of abstraction than the code itself.
Participants in our user study overall did explore a broader design space—but also were clearly overwhelmed by the sheer quantity of information LLMs can provide in this context. The challenge for future agentic IDEs will not just be better code generation, but also managing user attention, deciding what information to generate and show users, and how.
A precursor to this work also appeared at an ICML workshop—
Iterative Disambiguation: Towards LLM-Supported Programming and System Design ICML 2023 AI&HCI workshop [pdf | poster]
J.D. Zamfirescu-Pereira, Björn Hartmann
Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences UIST 2024 [pdf]
Shreya Shankar, J.D. Zamfirescu-Pereira, Björn Hartmann, Aditya G. Parameswaran, Ian Arawjo
LLM-based validation of LLM prompts is a classic “turtles all the way down” problem. In this work, we present EvalGen, a tool that adds one more turtle: LLMs generating LLM- (and code-)based evaluations of LLM prompts, finding that having criteria for success is critical to evaluating outputs—but generating these criteria requires evaluating outputs, a classic iterative design problem.
Work on EvalGen's underlying technology appeared at VLDB 2024—
SPADE: Synthesizing Data Quality Assertions for Large Language Model Pipelines VLDB 2024 Industry Track [pdf] Shreya Shankar, Haotian Li, Parth Asawa, Madelon Hulsebos, Yiming Lin, J.D. Zamfirescu-Pereira, Harrison Chase, Will Fu-Hinthorn, Aditya G. Parameswaran, Eugene Wu
This work has also generated quite a bit of industry interest and adoption—
Prompting for Discovery: Flexible Sense-Making for AI Art-Making with DreamSheets CHI 2024 [pdf]
Shm Garanganao Almeda, J.D. Zamfirescu-Pereira, Kyu Won Kim, Pradeep Mani Rathnam, Bjoern Hartmann
Existing Text-to-Image (TTI) models are typically wrapped in a limited single-input few-output paradigm.
DreamSheets embeds Stable Diffusion in Google Sheets, alongside a set of LLM-based functions also turns concepts (“colors”) into columns (“red”, “blue”, “green”, etc.). This enables:
- ...artists' custom interfaces to explore gigantic design spaces of prompts and images, creating “axes” to help organize
- ...rich history-keeping to track the impacts of prompt changes over far longer timeranges than the typical chatbox TTI interaction
An earlier version of this work also appeared at UIST—
Towards Image Design Space Exploration in Spreadsheets with LLM Formulae UIST 2023 demo track [pdf] J.D. Zamfirescu-Pereira, Shm Garanganao Almeda, Kyu Won Kim, Bjoern Hartmann

Rambler: Supporting Writing With Speech via LLM-Assisted Gist Manipulation CHI 2024 [pdf]
Susan Lin, Jeremy Warner, J.D. Zamfirescu-Pereira, Matthew G. Lee, Sauhard Jain, Michael Xuelin Huang, Piyawat Lertvittayakumjorn, Shanqing Cai, Shumin Zhai, Björn Hartmann, Can Liu
Why Prompting is Hard August 8th, 2023Data Skeptic Podcast
J.D. Zamfirescu-Pereira, hosted by Kyle Polich
Generative AI Salon #1: Human Rights Hopes & Concerns March 23rd, 2023Fight for the Future & Amnesty International [video]
J.D. Zamfirescu-Pereira, Shirin Anlen, Ken Mickles, and others
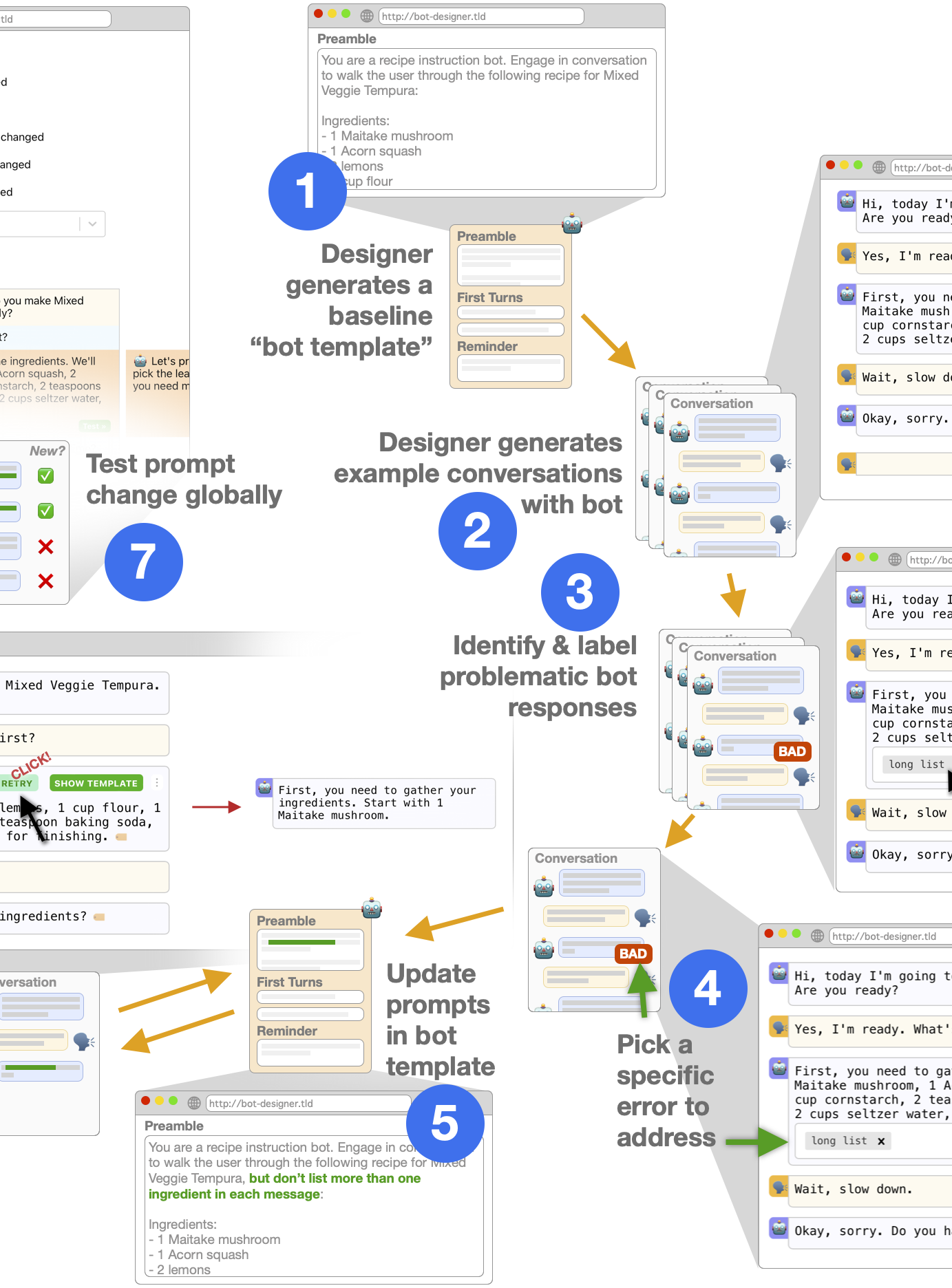
Why Johnny Can't Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts CHI 2023 [pdf]
J.D. Zamfirescu-Pereira, Richmond Wong, Bjoern Hartmann, Qian Yang
LLMs promise to universalize natural language input for computing systems. But is this true? How effective are non-experts at prompting LLMs to get what they want? What intuitions do they bring to prompting, and where do those get in the way?
We built a prompt-only no-code chatbot design tool (BotDesigner, but think “GPTs”) and observed participants successes and struggles, finding that people:
- ...bring expectations from human-human instructional interactions, and these are hard to let go of.
- ...overgeneralize from single positive or negatve examples of a prompt + input + LLM output.
An earlier version of this work was selected to present at a NeurIPS workshop—
Towards End-User Prompt Engineering: Lessons From an LLM-based Chatbot Design Tool Human-Centered AI Workshop @ NeurIPS 2022 Presented
J.D. Zamfirescu-Pereira, Richmond Wong, Bjoern Hartmann, Qian Yang
Herding AI Cats: Lessons from Designing a Chatbot by Prompting GPT-3 DIS 2023 [pdf]
J.D. Zamfirescu-Pereira, Heather Wei, Amy Xiao, Kitty Gu, Grace Jung, Matthew G. Lee, Bjoern Hartmann, Qian Yang
How effective are experts at prompting LLMs to get what they want? Our expert team used BotDesigner to build a cooking-instruction chatbot inspired by Carla Lalli's charming personal style in Bon Appetit's Back-to-Back Chef.
We ran in to brittleness at many levels:
- ...individial prompts for specific behavior often work, but effectivness is highly sensitive to phrasing and location within the overall prompt.
- ...prompts do not always combine in intuitive ways.
- ...getting GPT to say when it didn't know something was very hard.
Together, these led to highly prescriptive prompts—in many ways counteracting the purported flexibility of using an LLM to design a chatbot in the first place!
Democratizing Design and Fabrication Using Speech: Exploring co-design with a voice assistant CUI 2021 [pdf]
Andrea Cuadra, David Goedicke, J.D. Zamfirescu-Pereira
How can we make design and fabrication more accessible to non-experts? We built a Wizard-of-Oz voice assistant to help people design and fabricate a holiday ornament, and observed how people used it; seeing a preview of design-work-in-progress lowered expectations but increased satisfaction with the final fabricated orgnament.
CS Education + Support
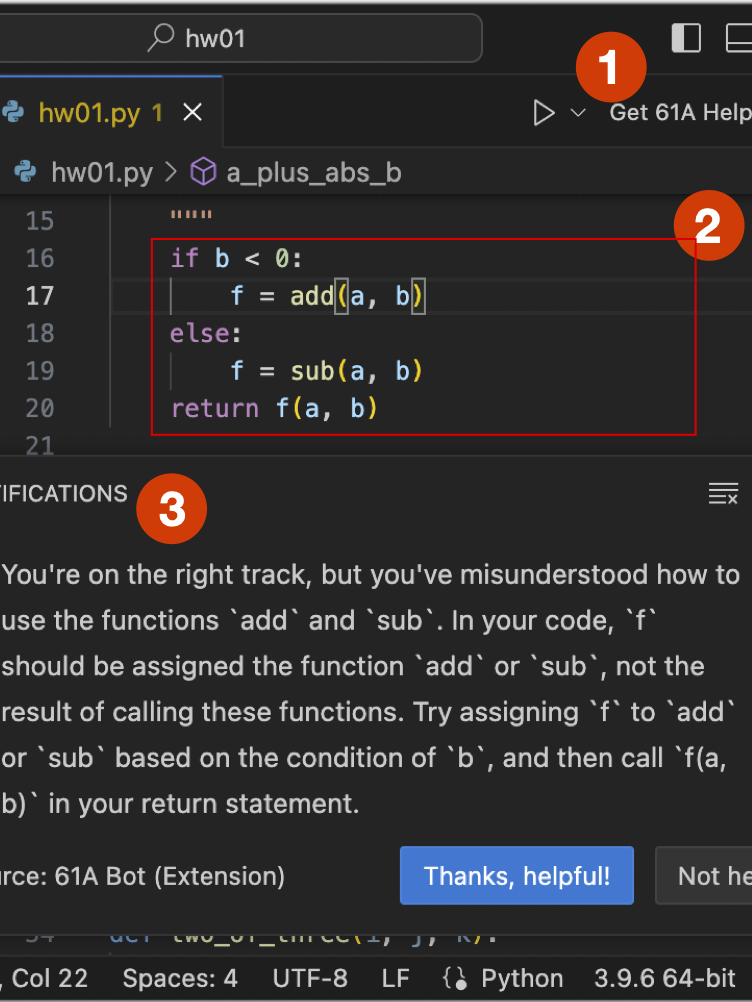
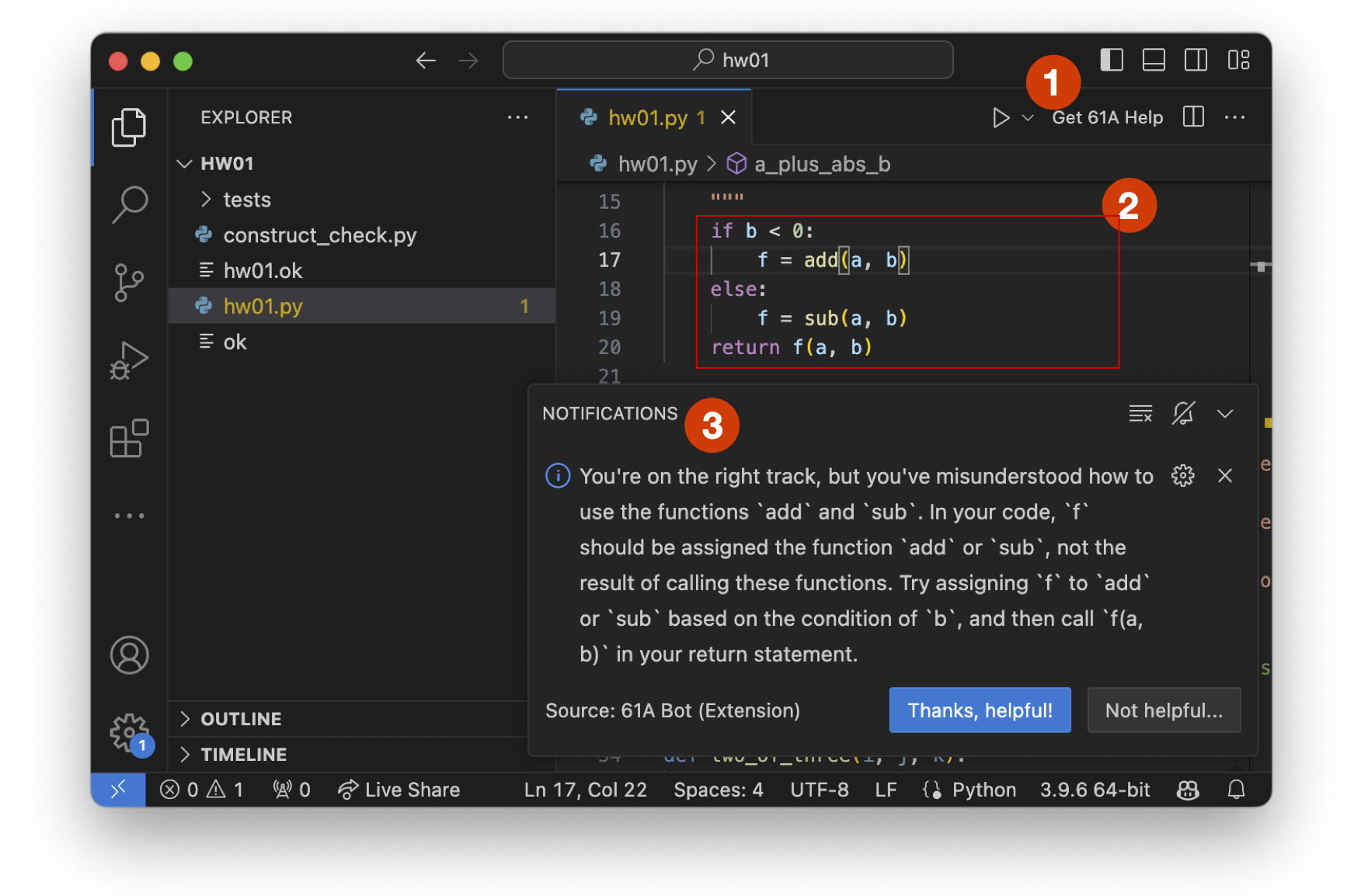
61A Bot Report: AI Assistants in CS1 Save Students Homework Time and Reduce Demands on Staff. (Now What?) SIGCSE TS 2025 [pdf]
J.D. Zamfirescu-Pereira, Laryn Qi, Bjoern Hartmann, John DeNero, Narges Norouzi
We deployed an LLM-based AI tutor for CS 61A, Berkeley's introductory CS course; in this paper under review, we share impacts on students and staff, finding reductions in homework completion times of 4 standard deviations below the mean pre-deployment, over 30 minutes in many cases.
An earlier version of this work also appeared at a NeurIPS Workshop—
Conversational Programming with LLM-Powered Interactive Support in an Introductory Computer Science Course NeurIPS 2023 Workshop on Generative AI for Education [pdf] J.D. Zamfirescu-Pereira, Laryn Qi, Bjoern Hartmann, John DeNero, Narges Norouzi
Heimdall: A Remotely Controlled Inspection Workbench for Debugging Microcontroller Projects CHI 2019 [pdf] Best Paper Honorable Mention
Mitchell Karchemsky, J.D. Zamfirescu-Pereira, Kuan-Ju Wu, François Guimbretière, and Bjoern Hartmann
Rudy the Red Dot
Rudy is a web-based IDE for learners of programming.
Intended to complement a course or workshop, Rudy helps teach the introductory concepts of procedural programming.
- Levels are designed to dispel common misconceptions about programming.
- Execution is highlighted to help students internalize the program counter and call stack.
- Global variables and function scopes are shown to help students see how execution changes state.
- Expression evaluation is illustrated by replacing subexpressions with evaluated values in real-time.